
Paper Reading: Embodied AI 1
从零开始的 Embodied AI 研究生活,第一批论文速记。
views
| comments
RT-1#
RT-1: Robotics Transformer for Real-World Control at Scale
把视觉语言条件下的动作预测统一到 Transformer 框架,是后续 VLA 的早期里程碑。
- 核心方法:图像+文本编码后做 token 融合,输出离散动作 token。
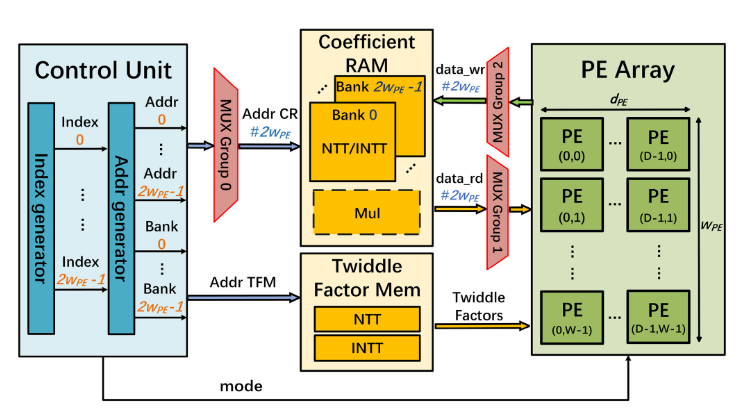
图中展示了该类方案的硬件架构思路。通过增加流水深度,可以减少 MUX 电路规模,从而降低资源开销。
- 价值:证明“大数据 + 统一架构”在机器人控制上可行。
- 局限:泛化边界与高层规划能力有限,依赖任务分布。
RT-2#
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
把 VLM 的语义能力迁移到机器人动作生成,显著提高了指令泛化能力。
- 核心方法:把动作表示成语言 token,与 VLM 的 token 空间统一建模。
- 价值:桥接了网络规模语义知识与实体执行。
- 局限:对执行稳定性和长时序任务仍有挑战。