
Paper Reading: Kyber 1
从零开始的 Kyber AI 研究生活,第一批论文速记。
SCNTT#
Scalable and Conflict-Free NTT Hardware Accelerator Design: Methodology, Proof, and Implementation
- 核心方法:针对二维 PE 阵列,扩充无冲突映射方法,并提供严谨的无内存冲突及无 RAW 冲突证明。
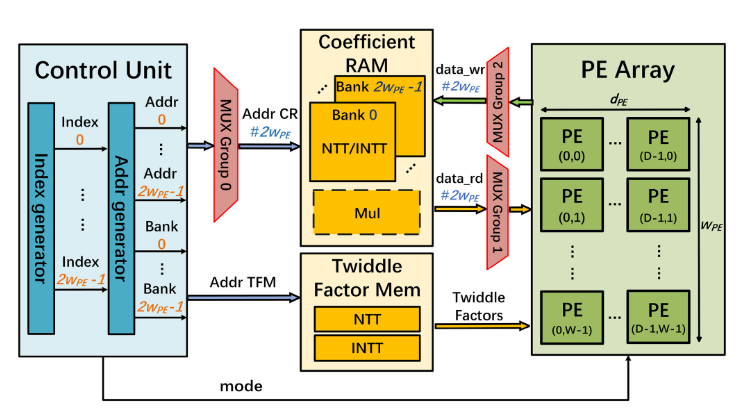
这张图展示了该篇论文的核心硬件架构。随着流水深度增加,所需 MUX 带宽可下降,从而降低资源开销。
让我们再上传一张图片,如下所示。你好,能看到我的修改吗
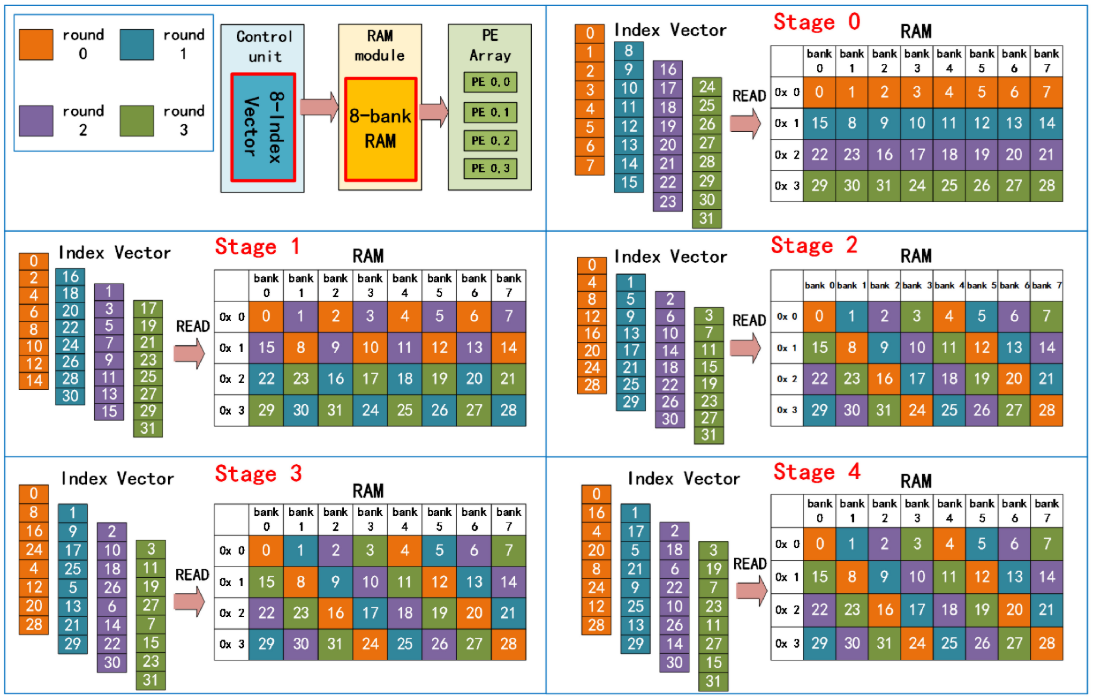
这张图片则是显示了其RAM的实际方案,也还算不错。
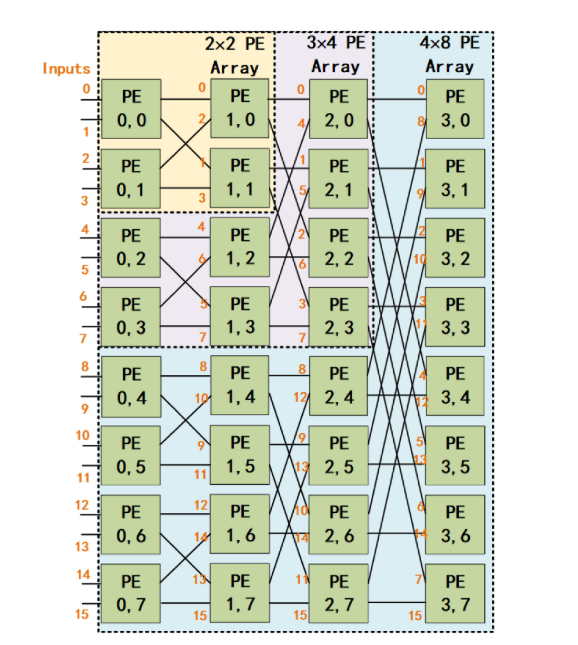 进一步地,我们来看一下他的PE阵列是怎么排放的。
进一步地,我们来看一下他的PE阵列是怎么排放的。
- 价值:当前方案很强,工程上可借鉴意义高。
- 局限:原文比较复杂,阅读门槛较高。
HS-NTT#
High-Speed NTT Accelerator for CRYSTAL-Kyber and CRYSTAL-Dilithium
是Mu文章的延续。 突出的贡献为将2323的乘法器,分解为4个1212的小型乘法器,并利用2^23等价2^12-1 mod q 特性实现折叠。在加法层面采用的是CSA。此外,统一了NTT和INTT结构,使得RU利用率从50%上升到100%。不过后面这个点显然是个幌子。以及实现了基2和基4的实现。核心图片为fig2.展示了其怎么实现Dilithium模数下的DSP分解。
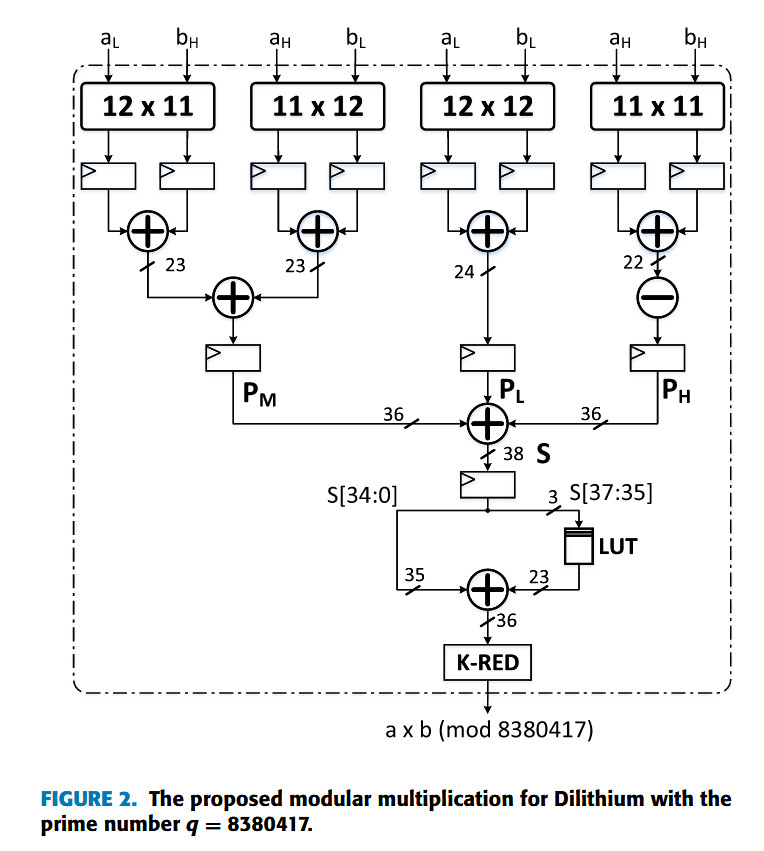 分解为四个小乘法。其中因为aH*bH天然具有2^23权重,因此作者利用2^23等价2^13-1 mod q ,将高位乘积折回较低位域。因此得到PM,PL,PH三部分。该部分与figrue1的部分积归并相关,建议回头仔细阅读。后续又进行了以此K-RED尾部约减。总体来说位分裂乘法+CSA归并+模数性质折叠+K-RED。
总体来说,大体知道了怎么一回事。但是具体原理还是需要仔细阅读。
分解为四个小乘法。其中因为aH*bH天然具有2^23权重,因此作者利用2^23等价2^13-1 mod q ,将高位乘积折回较低位域。因此得到PM,PL,PH三部分。该部分与figrue1的部分积归并相关,建议回头仔细阅读。后续又进行了以此K-RED尾部约减。总体来说位分裂乘法+CSA归并+模数性质折叠+K-RED。
总体来说,大体知道了怎么一回事。但是具体原理还是需要仔细阅读。
TCO-NTT#
A Timing-Constrained Design Methodology for Radix- 2<sup> <i>k</i> </sup> NTT in Polynomial Arithmetic
之前的NTT输出系数调度策略多为BFU出之后,存储到对应的bank中,要再次从bank中到BFU,需要采用permutation进行重排。而TCM-NTT(或成为TCO-NTT),则在TCM结构中,用memory写入顺序提前完成重排,在下一阶段BFU需要时直接读出数据,简单而言,就是用时间调度解决了空间重排问题。重排开销被塞进了目标时序约束框架中~
此外,通过sub NTT策略,实现了任意并行度和任意radix的支持。TCM同样支持任意并行度下的NTT设计。
对于核心fig3进行讲解:
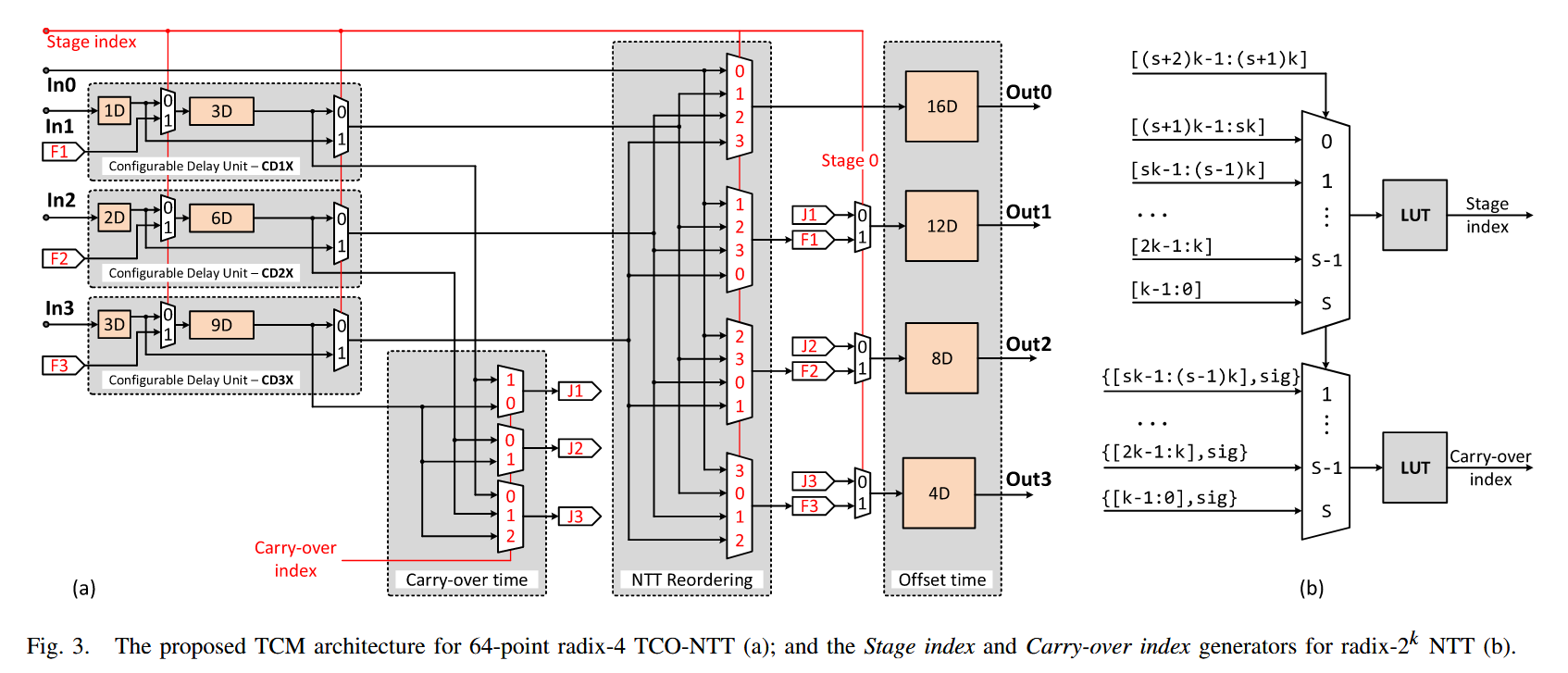 该图片是对于整体TCM架构机制的形象阐述。描述了我开头的数据是经过CD1~3X进行一个初步延迟,如果是在某些并行度和radix下,那么还需要Carry-over index进行跨stage的对齐,NTT-Reordering则是真正进行数据重排的结构,原理就是多路选择器!最后的offset time结构则是对整体进行一个对齐,确保到BFU单元具有一个统一的时延。
TCM的输入来自BFU的输出数据流,其输出则是送往下一stageBFU的输入数据流。并非完全没有存储开销,还是要存储一个多项式,但是也就仅仅只有这么一份开销了。
可见,经由TCM之后,数据自然而然完成了重新排列这个操作,不需要付出昂贵的mux以及bank代价,只需要付出少量的硬件开销以及时序约束为代价。
该图片是对于整体TCM架构机制的形象阐述。描述了我开头的数据是经过CD1~3X进行一个初步延迟,如果是在某些并行度和radix下,那么还需要Carry-over index进行跨stage的对齐,NTT-Reordering则是真正进行数据重排的结构,原理就是多路选择器!最后的offset time结构则是对整体进行一个对齐,确保到BFU单元具有一个统一的时延。
TCM的输入来自BFU的输出数据流,其输出则是送往下一stageBFU的输入数据流。并非完全没有存储开销,还是要存储一个多项式,但是也就仅仅只有这么一份开销了。
可见,经由TCM之后,数据自然而然完成了重新排列这个操作,不需要付出昂贵的mux以及bank代价,只需要付出少量的硬件开销以及时序约束为代价。
UP-NTT#
Unified-pipelined NTT Architecture for Polynomial Multiplication in Lattice-based Cryptosystems
所谓的“通过统一流水线结构让不同 stage 在同一数据路径上连续执行”,实际上就是搭建了一个全流水,而没有采用迭代架构。这样的好处就是减少了中间存储环节,以及数据搬运环节。针对潜在的DSP爆炸问题,作者巧妙地自定义了DSP结构,采用纯LUT实现,因此最后取得了不错的ATP指标。
流水线中包含两种基本单元,一个是BU,完成加减乘法的蝶形运算,一个是RU,完成延迟和数据对齐,因此BU和RU交替排列,从而实现整套系统。值得注意的是,NTT和INTT的数据流向恰好相反,这样也恰好实现了硬件结构的百分百利用。
核心开销的降低是L-DSP multiplier。类似之前的HS-NTT。这里是首先进行了高低位的拆解(Karatsuba分解),运算后期高位采用K-RED,采用LUT实现模约减。
下面对fig2进行讲解:
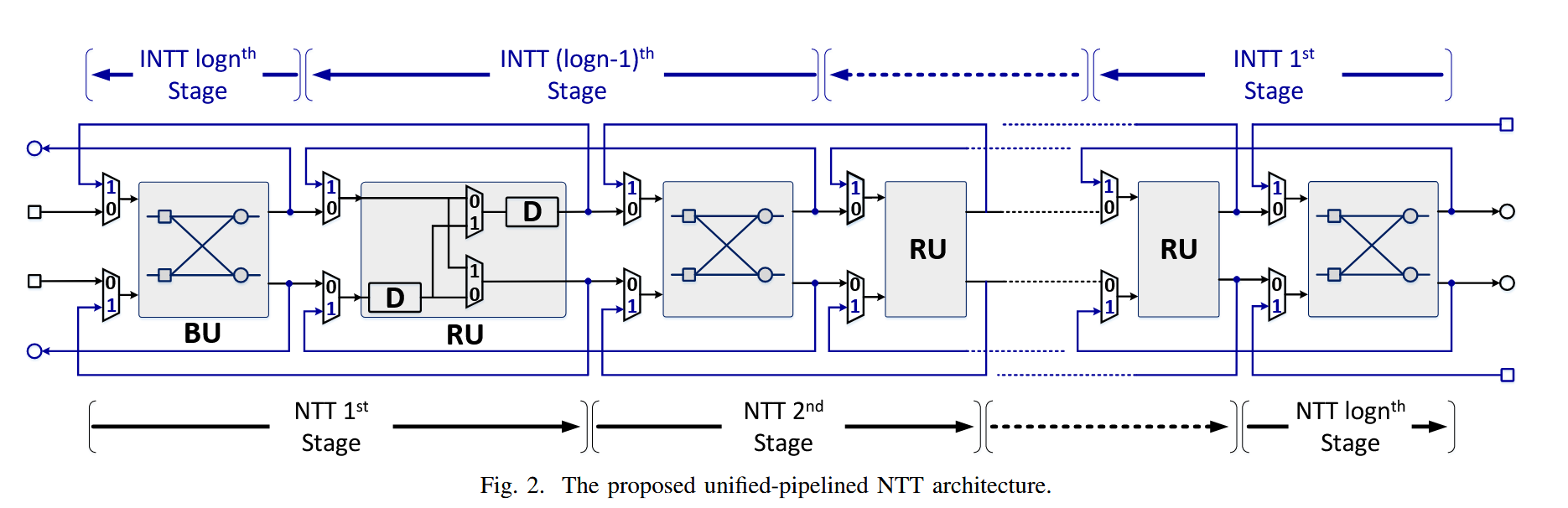 显然,这是方向可控的pipeline。NTT/INTT时方向恰好相反,要实现这一点,就是要依托方向可控的MUX以及对称延时配置。此外,如果做forward/inverse分开的设计,那么RU利用率只有50%。
显然,这是方向可控的pipeline。NTT/INTT时方向恰好相反,要实现这一点,就是要依托方向可控的MUX以及对称延时配置。此外,如果做forward/inverse分开的设计,那么RU利用率只有50%。
RU的本质就是做了一个移位寄存器+切换网络的功能,即把之前的重排,转换为了数据流中的延时对齐问题,这个就有一些后面TCO-NTT的影子了。
UP-NTT这篇文章虽然短小精悍,但是其中透露出来的研究线索,都可以作为单独的文章发表。例如时序延迟对齐-TCO-NTT,以及L-DSP的进阶版本(适应不同的参数q,以及保持这种分解的思路)-HS-NTT。
EL-Kyber#
Efficient Hardware Implementation of the Lightweight CRYSTALS-Kyber
这篇文章主要解决了三件事情:
1.紧凑的hash模块
2.非存储的iterative NTT,即NMI-NTT
3.高效的,并发的控制流。表现为前端随机数产生,采样,和后端的NTT。PWM操作并发。
-
讲解NMI-NTT
传统的迭代型架构为数据从bank读出,经过路由打回BFU。这个本质上就是一个数据重排以及缓冲的操作,因此完全可以有一个重排序单元完成,因此引入RU(实现了延迟+反馈重排)。省去了多余的RAM以及路由网络。 这个RU单元是这个作者用的非常多的方法了,也比较好用。 算是结合了iterative和pipeline架构的优点吧!pipeline的经典架构是MDC/SDF,需要多级流水,硬件开销庞大!iterative的经典架构例如pingpong,无冲突地址映射等,但是都需要存储开销以及路由,免不了由BRAM!但是这个NMI-NTT就做的很棒!采用延迟线完成阶段间重排这样一个核心任务! -
讲解hash模块
采用25*64bit 寄存器承当装载,轮函数计算和输出工作。 -
讲解控制流调度
对于哈希,采样,NTT,PWM,INTT,压缩。将其次序重排。哈希是很慢,但是生成下一项的过程和计算当前项(后者由采样和NTT)过程可以重叠,因此可以用调度隐藏哈希慢的问题。
接下来讲解fig6:
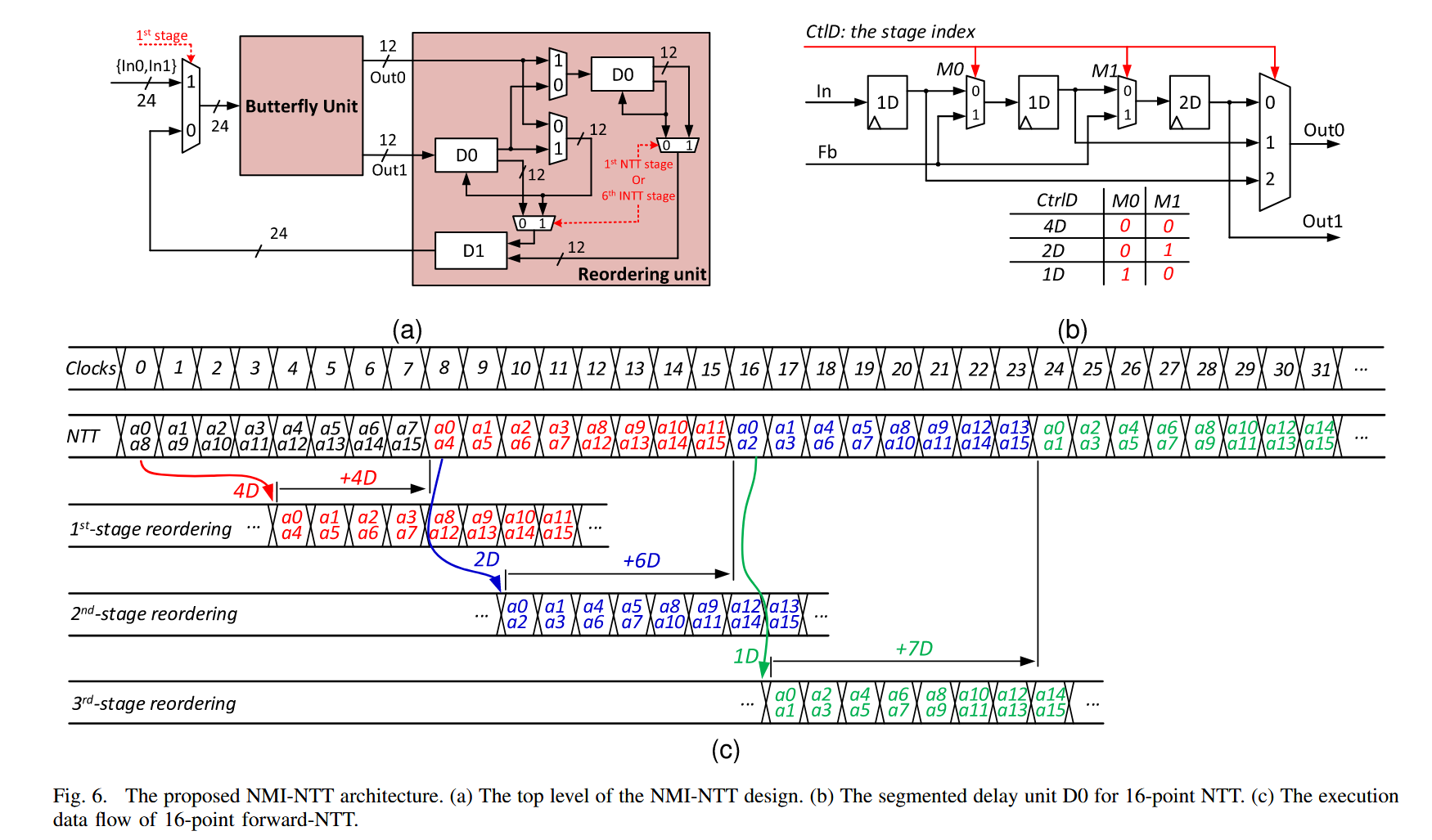 (a)中重点讲解了单个stage内的RU是如何构成闭环的。这里重点讲一下为什么要进行延迟重排,以及BU出来的数据为什么需要对齐这个事情(即BU的两个操作数同一时刻到达,正好构成该stage所需的蝶形配对)。
在蝶形单元运算中,我们每个stage都需要计算256个点,如果是双路的话,每个蝶形需要计算128个点,这128个点,单个时钟周期只会输出两个点,但是输出的两个点并不一定就是下个周期紧接着需要的两个点,因此为了在下一周期(实际上更宽广,为了下一个stage)还能进行正确的BFU计算,需要进行额外的等待。等待的时钟周期是确定的,且和当前的stage有关,因此,为了完成正确的数据配对,所需要等待的时钟周期有2,4,8。对于 BU 输出的两路数据,RU 会根据当前 stage 的目标配对关系,选择不同的延迟路径,使两路数据在经过 D0、D1 及反馈后,于正确时刻重新配对并送入下一轮 BU.
(a)中重点讲解了单个stage内的RU是如何构成闭环的。这里重点讲一下为什么要进行延迟重排,以及BU出来的数据为什么需要对齐这个事情(即BU的两个操作数同一时刻到达,正好构成该stage所需的蝶形配对)。
在蝶形单元运算中,我们每个stage都需要计算256个点,如果是双路的话,每个蝶形需要计算128个点,这128个点,单个时钟周期只会输出两个点,但是输出的两个点并不一定就是下个周期紧接着需要的两个点,因此为了在下一周期(实际上更宽广,为了下一个stage)还能进行正确的BFU计算,需要进行额外的等待。等待的时钟周期是确定的,且和当前的stage有关,因此,为了完成正确的数据配对,所需要等待的时钟周期有2,4,8。对于 BU 输出的两路数据,RU 会根据当前 stage 的目标配对关系,选择不同的延迟路径,使两路数据在经过 D0、D1 及反馈后,于正确时刻重新配对并送入下一轮 BU.
(b)就是讲解了D0的内部组成。
(c)则是讲解了当后续 stage 所需 delay 变小时,多出来的系数存哪?会不会下一拍和新进数据冲突?然后可以看出,reordering是很快的,可以把RU中的数据存起来,等到NTT真正运算需要的时候再给送出去。这个方式实现的核心就是feedback,可以把本阶段暂时不用立刻输出的系数重新送回 D0 中的未使用段
AMR-NTT#
Area-Efficient Modular Reduction Structure and Memory Access Scheme for NTT
作者针对广义梅森素数约减逻辑空白,以及现有访存方案复杂度太高的问题,提出AMR-NTT架构,实现了面积效率优先的NTT方案。
首先介绍访存方案,如下图所示:
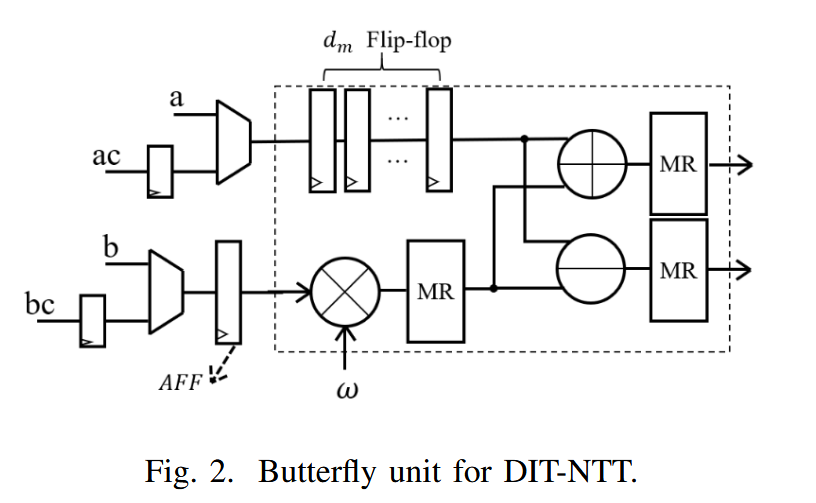
radix-2情况下,传统为同拍下读取a,b两个系数进行运算(所谓的两侧数据),改进后为当前拍子只取一侧数据,但是取两个,即a,ac。然后通过缓存机制实现数据的自动对齐,下一拍再取b,bc。因为不同stage,要得到两侧数据的对齐时间不同,因此引入dm参数控制延迟拍数。对于同拍,ac延迟a一个时钟周期,bc延迟b一个时钟周期。
对于模约简方案,针对广义梅森素数进行了化简,最终只需要判断三种情况应用哪一种,(即单bit就能判断是否进行约减),传统为对整个64bit数运算。如下图所示
其中c为提出方案,可见节约了加法器逻辑,predict logic即为单bit生成,以及具体的模约简计算。
 2026年3月24日,对于文章重新进行查看
关于广义梅森素数,还可以看这个维基https://en.wikipedia.org/wiki/Solinas_prime ->
之前关于SN-BCC这篇文章已经初步地阅读过一次了,当时是skim状态。现在针对其中的广义梅森素数章节继续进行深入地阅读。
2026年3月24日,对于文章重新进行查看
关于广义梅森素数,还可以看这个维基https://en.wikipedia.org/wiki/Solinas_prime ->
之前关于SN-BCC这篇文章已经初步地阅读过一次了,当时是skim状态。现在针对其中的广义梅森素数章节继续进行深入地阅读。
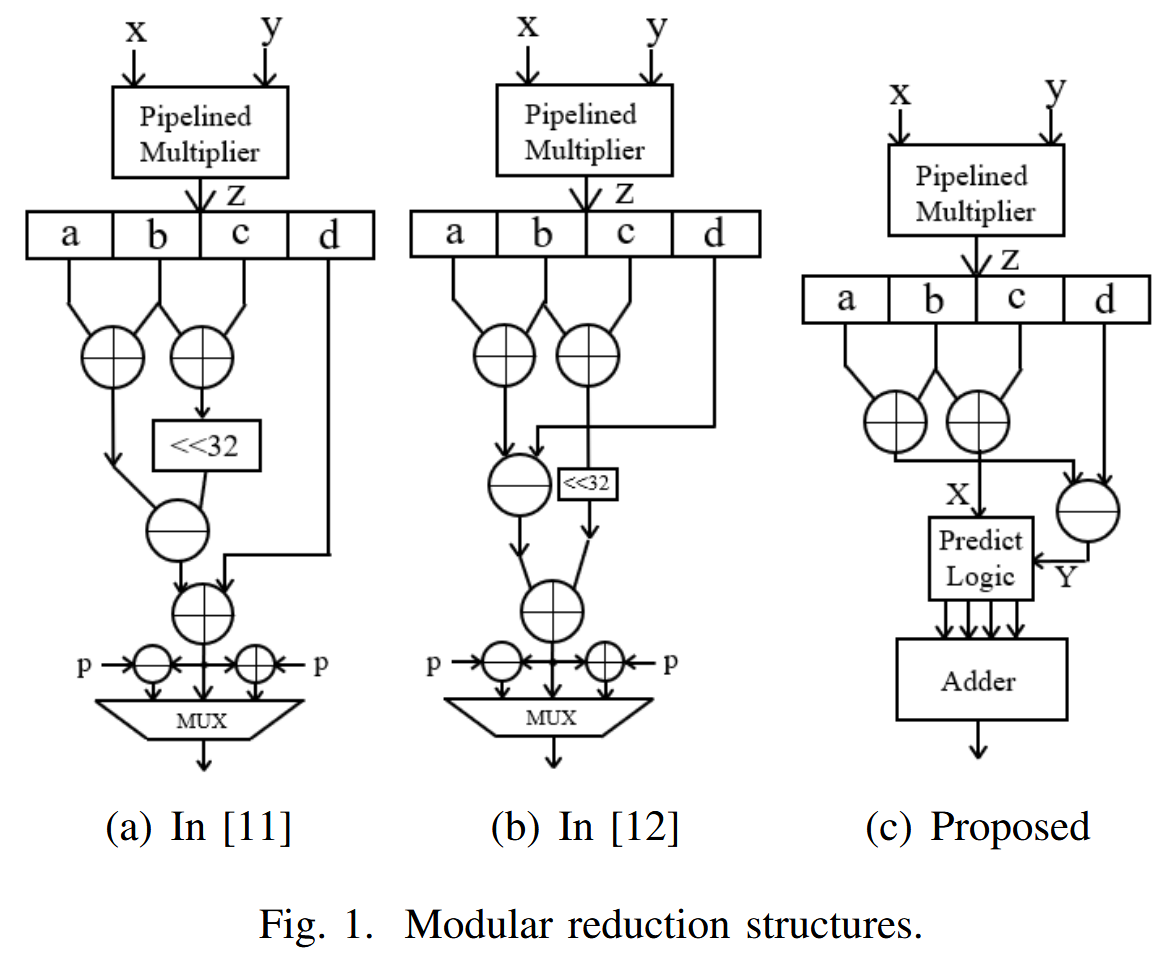
对于128bit 的数z,可以表达为这种2^32进制的形式z = 2^96a + 2^64b + 2^32c + d。其中abcd都是2^32的数字。对p=(2^32-1)2^32+1进行模之后,剩下的部分就表达为公式3中所示
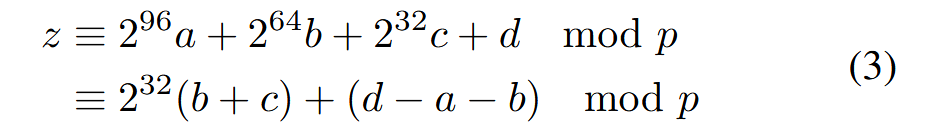
进一步地,作者和[11]和[12]都指出,这个约减后的结果不一定落在p内,因此分别提出了其进一步约减的电路。也就是上上图。
作者Guo对此也有研究,他进一步的指出b+c在不同范围下,需要何种基于p的补偿操作。为了表达的方便,其定义X=b+c,Y=d-a-b。这样做视为了后续进一步定义的方便。
后续,Guo进一步定义了ABCDEF,用来表示X和Y的一些特征。这时候发现,根据ABCDEF的不同取值(捷尔和之前多b+c的范围讨论),最终可以确定是+p,还是-p,还是不变。实际上就加和减两种状态,因此刻画了一个真值表,也就是输入为ABCDEF,输出为加或减标志位,也就是ct1,ct2。关于模约简中的数学相关推导到这里就结束了.
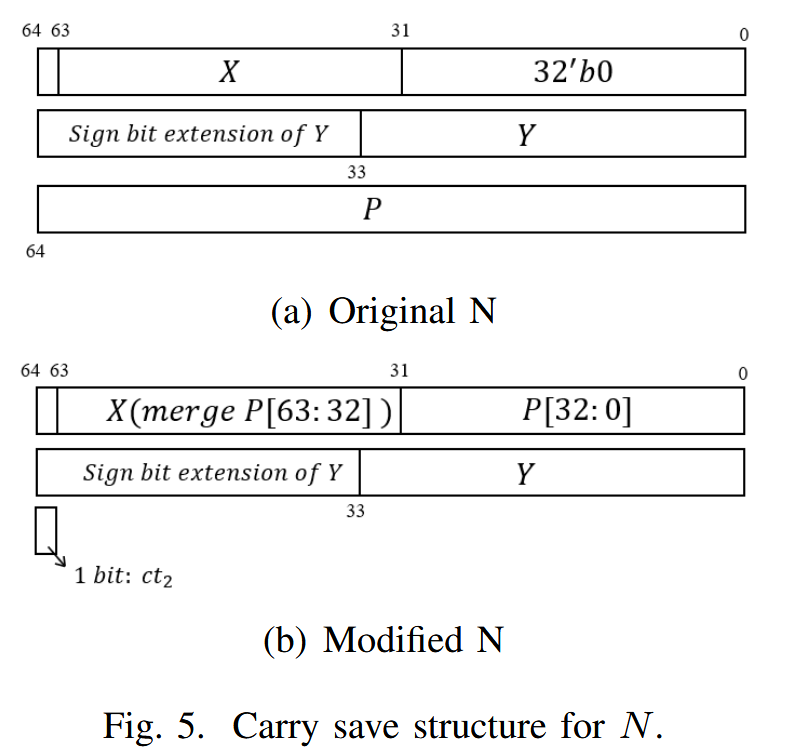 但是Guo毕竟是做硬件出身的,他又进一步地发现这个模约简器可以进一步地简化。可以看到,原始版本是需要存储3行数据,但是仔细发现后,可以将非常规范地P融入到X中。先来看P的构造:+p = 0xffffffff00000001,−p =0x100000000ffffffff。发现+p的时候,必须X=0,这时候完全可以直接融入。当-p的时候,因为X低32bit为0,因此可以融入,对于X高32bit,-p不会对其造成影响。总而言之,P可以实现融入!
但是Guo毕竟是做硬件出身的,他又进一步地发现这个模约简器可以进一步地简化。可以看到,原始版本是需要存储3行数据,但是仔细发现后,可以将非常规范地P融入到X中。先来看P的构造:+p = 0xffffffff00000001,−p =0x100000000ffffffff。发现+p的时候,必须X=0,这时候完全可以直接融入。当-p的时候,因为X低32bit为0,因此可以融入,对于X高32bit,-p不会对其造成影响。总而言之,P可以实现融入!
CFNTT#
CFNTT: Scalable Radix-2/4 NTT Multiplication Architecture with an Efficient Conflict-free Memory Mapping Scheme
作为第一篇完整阅读的NTT文档,还是有些感情的,后面才渐渐发现自己的知识库还是太浅太浅了。
-
核心方法:4分支无冲突公式映射。
- 价值:适合新手入门。提出的采用基2BFU实现基4BFU确实是一种比较好的方法
- 局限:不具有很亮眼的表现。
RT-1#
RT-1: Robotics Transformer for Real-World Control at Scale
-
核心方法:图像+文本编码后做 token 融合,输出离散动作 token。
- 价值:证明“大数据 + 统一架构”在机器人控制上可行。
- 局限:泛化边界与高层规划能力有限,依赖任务分布。
RT-2#
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
-
核心方法:把动作表示成语言 token,与 VLM 的 token 空间统一建模。
- 价值:桥接了网络规模语义知识与实体执行。
- 局限:对执行稳定性和长时序任务仍有挑战。
NIST-PQC-Survey#
NIST抗量子密码标准候选算法中基于格的公钥加密与密钥封装机制介绍
一篇综述性质的扫盲文章,目的是建立 PQC 领域的整体 map,不涉及具体的算法性能改进。
理论背景与研究路线
- 2015 年,Langlois 等人 [10] 研究了模上错误学习问题(module-LWE, MLWE),并将 MLWE 问题归约到模格上的困难问题。
- 整体研究路线大致为:
- 基于 LWE 的 Regev 公钥加密方案 —— NIST 中的类 Regev 方案如 Titanium,但公钥太大,严重影响效率。
- 在加密过程中加上随机噪音并重用 LWE 假设以保证方案正确性,得到 LP 公钥加密方案,相比 Regev,公钥/私钥大小小
log q倍。 - 基于 2010 年 Lyubashevsky 等人提出的 RLWE 问题,给出了 LP 方案的环版本。
- NIST 标准中类 LP 方案有:FrodoKEM、KYBER、NewHope、SABER、NTRU Prime 等。
- 根据格困难型假设可进一步分为 5 类:
LWE/R、RLWE/R、MLWE/R、NTRU/R、Integer-MLWE/R,后文也以此对加密方案进行区分。
不同假设的对比
- RLWE:基于环上错误学习,底层多项式环采用指数为 2 的幂的分圆环。改变安全等级时不灵活,需要更换底层环;与 LWE 类似,通信成本较大。
- MLWE:Kyber 即为 MLWE 方案,可视为高效 RLWE 与安全 LWE 之间的折衷。
- I-MLWE:性能很好,但安全性尚未得到严格证明和认可。
- NTRU:2011 年 Stehlé 等人指出,若密钥多项式由离散高斯分布通过拒绝采样抽取,则安全性等同于 RLWE。优势在于封装/解封装快;劣势是密钥生成阶段需要多项式求逆,相比 RLWE / MLWE 慢。
- LWE vs LWR:LWR 通过 round 技术将大模数舍入到较小模数,因此相比 LWE 密钥/密文规模更小,带宽和内存需求也都更小,适合内存有限系统。
结构化格 vs 非结构化格
- 结构化格(MLWE/R、RLWE/R、NTRU)相比非结构化格 LWE,时间效率普遍更高;但 NTRU 需要执行多项式乘法,密钥生成较慢。
- 因为带结构,MLWE/R 与 RLWE/R 在理论上安全性低于 LWE。两者性能相似,但 NIST 更倾向 MLWE/R —— 结构更少,对应需要更高的理论安全性。
Q&A
Q1:尽管我现在对于各个方案的性能有了大致的了解,并且也大致知道可以分为两个大类,即具有结构环的,和不具有结构环的。但是我对于方案的具体区分还不知道,例如RLWE是在LWE上做了什么改进才被称为RLWE的?同理MLWE和NTRU(这里存在一个假设就是我认为其余结构化格都是在LWE基础上改进的,不知道对不对)?
- LWE 核心方程:
b = A·s + e (mod q),其中 A 是公钥矩阵,体积巨大(约 9KB)。 - RLWE:把 A 换成环上的一个多项式 a:
b = a·s + e (mod q, x^n + 1),公钥缩小约 n 倍。 - MLWE:不再用单个多项式,而是用多项式构成的小矩阵:
b = A·s + e,其中 A 是 k×k 矩阵,每个元素都是R_q中的多项式。 - 因此 MLWE 是 LWE 与 RLWE 中间的折衷:
k = 1时退化为 RLWE,n = 1时退化为 LWE。 - NTRU 的历史比 LWE 还要早。
Q2:这篇文章主要是扫盲,不涉及具体密码算法性能改进,对吗?
- 对。主要目的是了解 map,建立全局视角。
HP-MR-NTT#
High performance mixed-radix NTT design for post quantum cryptography
这个小子也想做混合radix方案? 就是说 NTT对于加速多项式乘法很重要,然后他提出了一种新颖的混合基NTT/INTT算法以及一种统一的硬件架构。具体而言就是应用到了2*2PE阵列的蝶形单元减少开销。模乘器是资源共享的,然后内存方案是专门制定的。
我要专门学习一下他是怎么描述混合基方案的了! 多项式乘法是PQC方案中计算开销最昂贵的操作。
尽管引入NTT数论变换可以显著降低PQC方案中的计算复杂度,但多项式乘法计算速度仍然是制约实际应用的主要因素。
为了加快NTT运算速度,最常见一种方法是采用多个基数为2的蝶形单元(BFUs)并行工作。然后列举系列工作。 然而,此类工作虽然提高了计算速度,但是付出了依赖多个蝶形单元资源凯西奥增加地代价。 相比之家,高基数算法能在节约资源的同时提升速度。然后列举系列工作。 然而,这种方法存在严格的多项式长度限制。为了解决这个问题,提出了混合基数算法。然后列举相关工作。 然而,现有的混合技术方法对于不同的格基方案缺乏灵活性。我们提出了一种高效的混合基数NTT架构,适用于高性能计算。然后就开始列举他自己的贡献了。
综上,我感觉这个很适合引出他自己的混合基方案设计,但是明显并不适合我们的论文!因为我们的首要卖点是循环解耦这个架构层面的设计!然后在是radix2/radix4!然后再是存储方案!
该paper中为Kyber采用了与Dilithium相同的方案,而没有处理Kyber的特殊一次多项式乘法环节。而且可以显著地看出,在切换为radix-2 BFU时,无论是乘法器,还是模加模减,都存在50%地浪费。
Questions:
- 它这个方案里面应该是没有考虑一次环下多项式乘法吧。也就是无论是Dilithium还是Kyber,实际上都是采用的相同的调度流程?
是这样的,作为一个缺陷咯
- 核心方法: