
Paper Reading: Reduction 1
从零开始的 Reduction 模约简 研究生活,第一批论文速记。
EF-PB-AM#
Energy-Efficient Approximate Multiplier Design With Lesser Error Rate Using the Probability-Based Approximate 4:2 Compressor
是一篇近似压缩器的文章,用来了解下主modular分支之外的约减也是不错的。小白适合阅读的文章!
所谓的权重等价,就是按照1的个数将16种输入状态等价为6种,其中2占了两种。这部分的硬件结构对应叫做重排序电路,实际上就是8个门组成的电路,搭建原理就是真值表。
所谓的低概率规范状态做近似,就是专门调了1100+1111/1110+1111两种情况做了两种design,按照1的个数越多,错误概率越小进行挑选的。最后得到了错误概率虽然不是最小的,但是最节能的设计方案。
接下来对表4,5,6,图1进行讲解
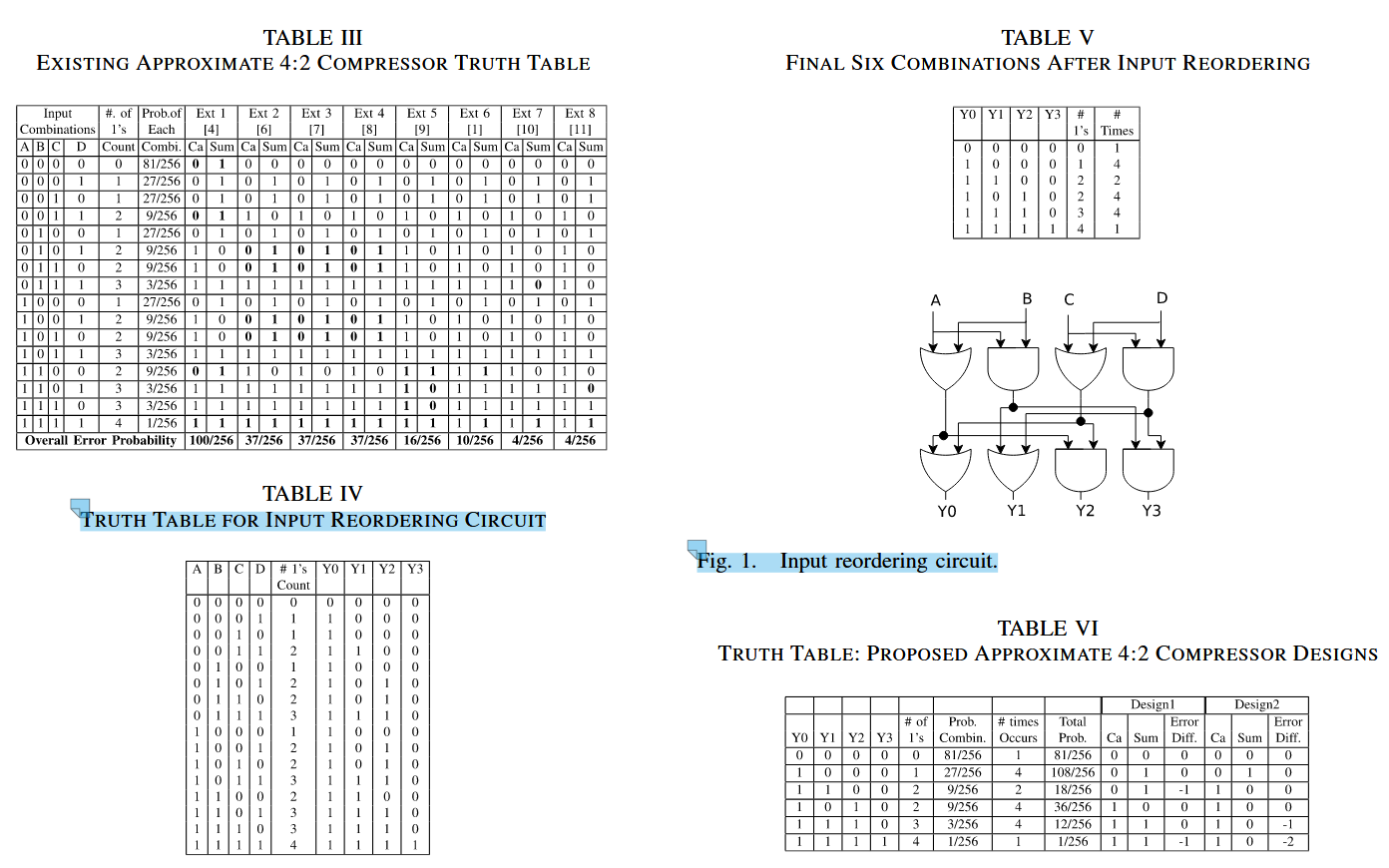
表4就是重排序电路的真值表,图1就是根据真值表得到的电路。
表5就是对表4继续进行了统计,值得注意的是times指标,这是以前的旧方法喜欢用的指标,实际上作者用的是概率,而非简单的次数。
表6则是考虑了表3后,进一步得出的两种设计方案。值得讲解的是,这里的Ca,和Sum是特定的,也就是经过精挑细选的,并且由此可总结一张真值表,用于完成Y0123→Cay/Sum的映射,得到的映射公式如(1)(2)所示,见下图。
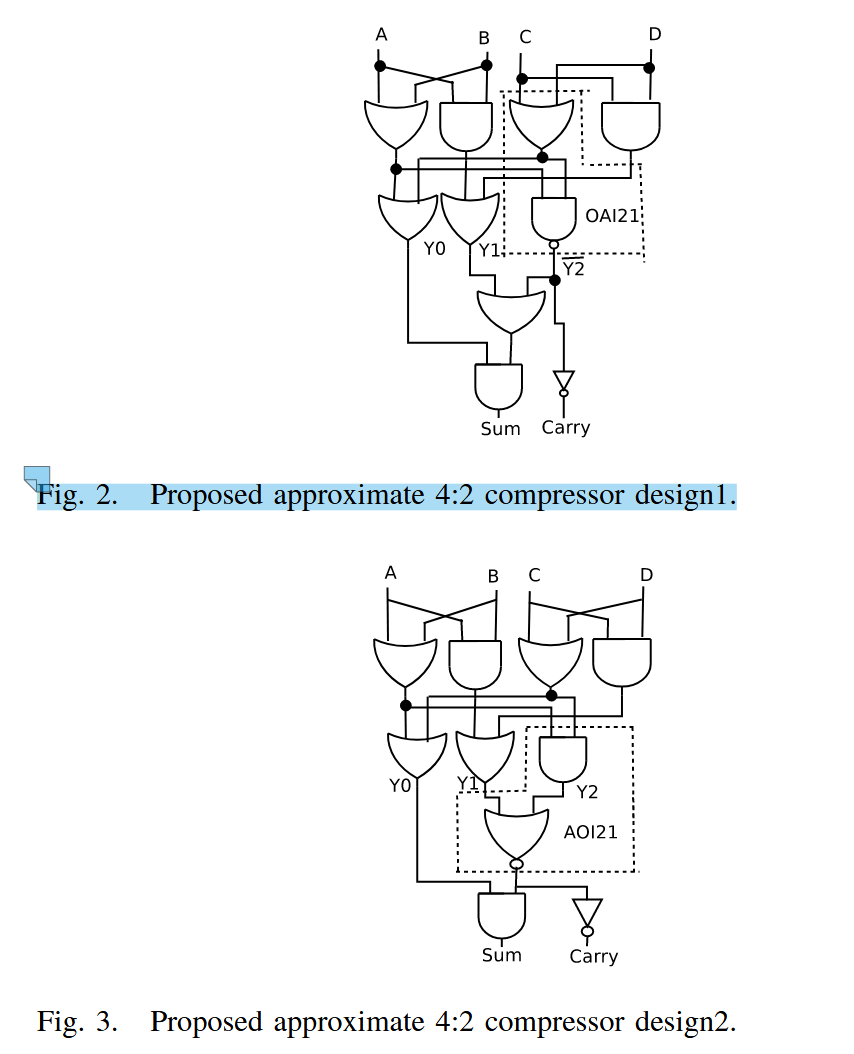
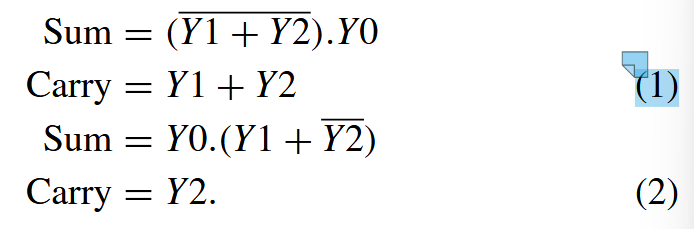 所以我们现在有了ABCD→Y0123的映射,又有了Y0123到Carry/Sum的映射,所以构建的电路如下,就是按照两套映射走的。
所以我们现在有了ABCD→Y0123的映射,又有了Y0123到Carry/Sum的映射,所以构建的电路如下,就是按照两套映射走的。
 继续的,我们讲解一下fig4,虽然说fig1是整篇文章的最突出的创新点,但是对于新手而言,fig4包含了重要的信息。
继续的,我们讲解一下fig4,虽然说fig1是整篇文章的最突出的创新点,但是对于新手而言,fig4包含了重要的信息。
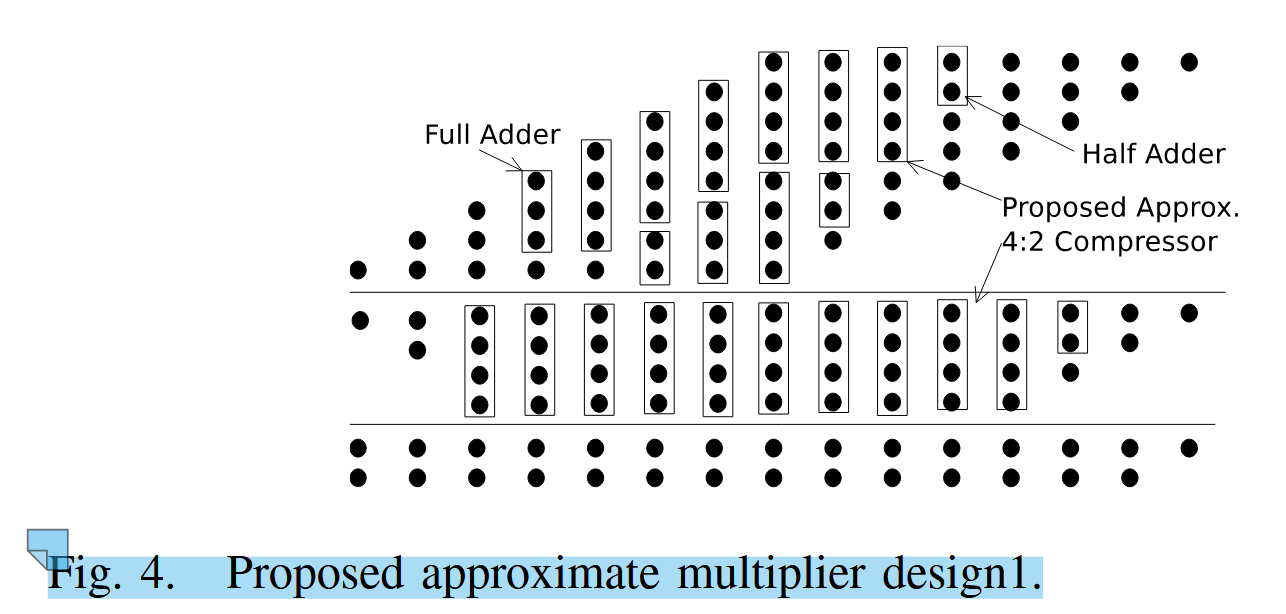
首先分为了上下三层,从上到下依次为:原始的8*8部分积展开,深8行,有15列;经过一次处理的部分积,可见深度已经变浅了许多;处理完成的两行部分积,只需要用一个普通的加法器就可以得到最终的乘法结果。那么为什么要采用reduction tree结构呢?因为乘法器里最麻烦的不是生成部分积,而是:某些列里 bit 太多了,不能直接一次加完。因此最佳的做法就是先进行压缩,只剩两行时用普通的加法器做最终结果。需要注意的是,用到的三种部件都会对高位列产生影响,也就是作用完成之后本列增加一个点,隔壁列也会增加一个点。
讲解到这里差不多就结束了,算是比较充分的理解了一下近似压缩是怎么一回事,不过咱们要做的是比特模,而不是这个。
顺便把table1也讲解一下。
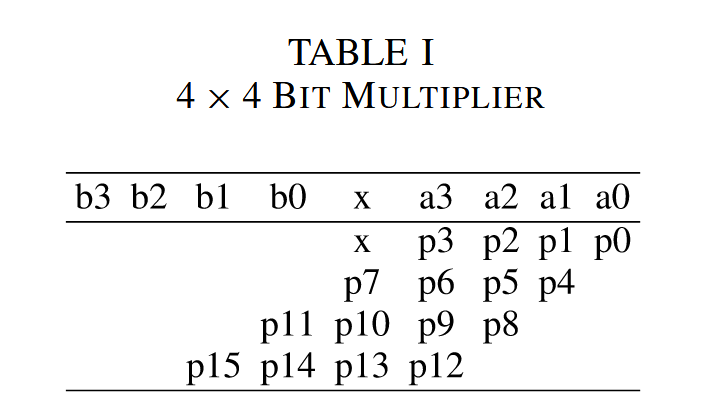 这个的话主要的疑问就是这个x是什么东西,直接说了:x就是乘号。然后给出这个图的意思就是要应用half adder,full adder,以及4,2 compressor。
这个的话主要的疑问就是这个x是什么东西,直接说了:x就是乘号。然后给出这个图的意思就是要应用half adder,full adder,以及4,2 compressor。
值得借鉴的经验就是利用对称性,非对称性,减少无效翻转和路由复杂度。
其实你现在做的电路的一个明显可以优化的地方就是对于路由网络进行剪枝,他现在的有效翻转状态实在是太少了!
这篇paper有讲解视频:https://ieeexplore.ieee.org/document/10136817 ->
Dadda-Bitmod-MR#
An Efficient and Low-Cost Design of Modular Reduction for CRYSTALS-Kyber
与前人的主要区别就是,进一步压缩了tree中的bit数目,以及tree树的层数,前两人研究的,虽然都是bitmod层级的,但是树的高度为4层。
值得注意的是,在bit tree层级,通过冗余消除,把负项,重复项和可拆分项都在tree的层面提前处理,这是得到低树高的关键。超权重项继续回代、同列正负项直接抵消、以及利用 2^m*c_m=2*2^{m-1}*c-M 做拆分/合并。
文章进一步拓展:
1.声称三种冗余消除方法可以迁移,但是并没有给出真正的可迁移实现
2.上述的三种冗余消除方法,缺乏更加学术化的表达,需要进一步包装一下。
3. 推广到Dilithium/Falcon。甚至FHE等场景。
接下来回答几个关键问题,以及讲解几张关键图片。
Q1:文中提到的三种冗余消除方法,到底怎么理解?有没有例子?
method3就是把三个点化简为两个点,同时换列,以及符号改变
method1。还是不太懂
method2容易理解,不再赘述
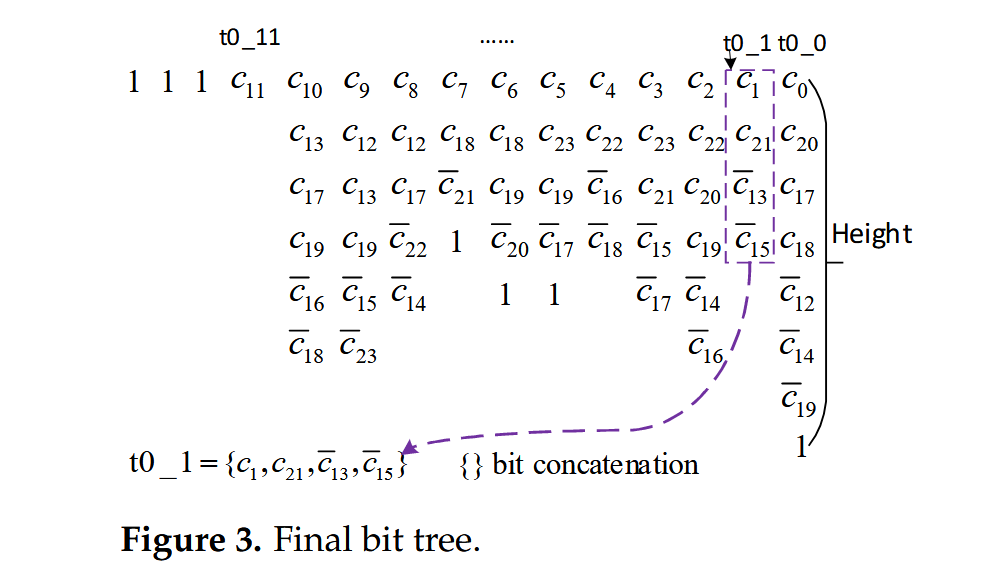
Q2:负数转补码环节为什么要+1?又是怎么最后进行简化,得到final bit tree的?
因为二补码恒等式,就是先取反,再+1.因此出现的低位1,一部分是这么来的。第二层就是位宽上的多1bit。原始两个12bit数相加,最大要到14bit,现在多1位符号位,成为15bit。
对于最后的finalbit处理,是这样的。1个列上如果有多个1,直接按照普通二进制加法处理。然后图2右下角的两个1也是因为转补码后+1得到的。
给出fig1到fig3的表达。


关键图片讲解:
fig1:已经在Q1中讲解过了。同理fig2,fig3
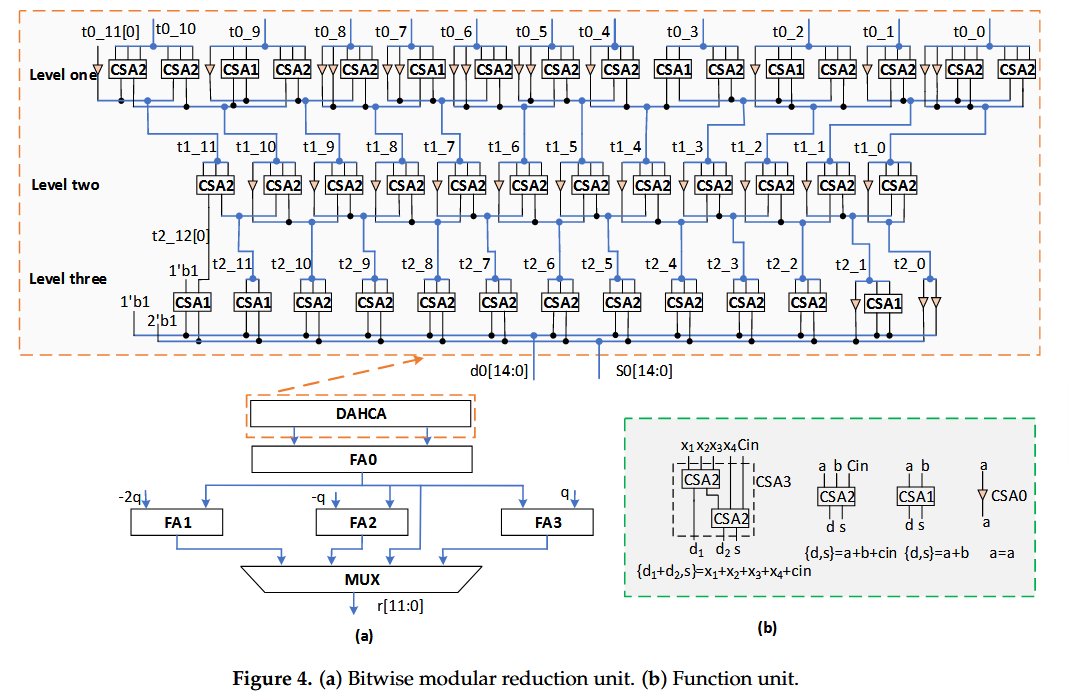
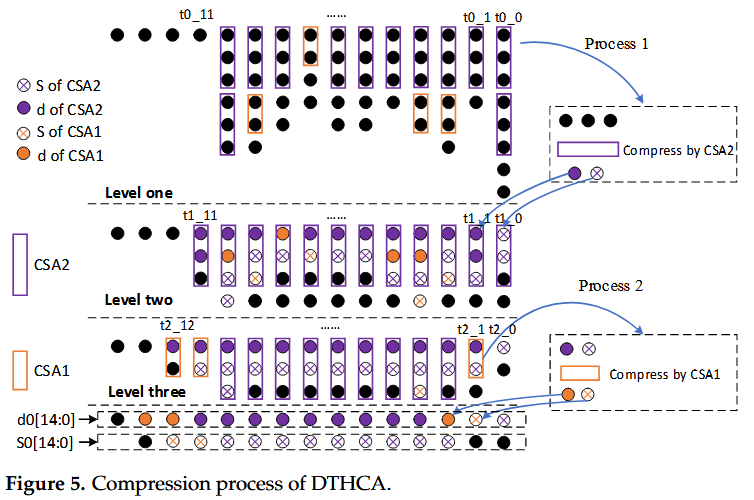
fig4:本文的主要硬件工作都在这张图片中,实际上就是fig5图片的另一种表达方式。CSA3虽然在ASIC中非常有用,但在FPGA中串行的双CSA2结构将会引入关键路径。CSA2和CSA1则有用的多,CSA0则是虚拟的,实际上就是硬连线。fig5就是对应的更加传统的压缩树表达。
- 核心方法: